A Inteligência Artificial que vende no piloto automático

Torne seu WhatsApp um marketplace rentável. Ajude seus clientes a encontrarem o que precisam, onde quer que estejam. Vender online nunca foi tão fácil.

A Inteligência Artificial que vende no piloto automático
Torne seu WhatsApp um marketplace rentável. Ajude seus clientes a encontrarem o que precisam, onde quer que estejam. Vender online nunca foi tão fácil.
Clientes que já fazem parte desta revolução

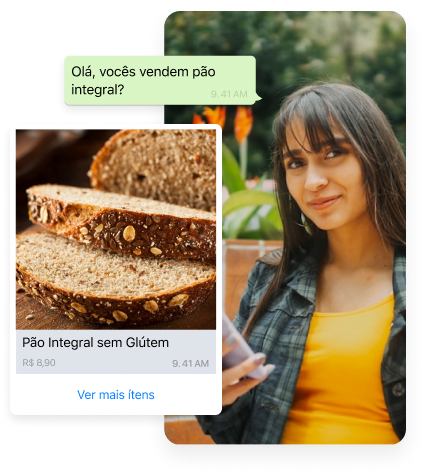

Não dependa de terceiros para vender os seus produtos. Automatize toda a jornada de venda pelo WhatsApp e torne-se 37x mais rentável.

Transforme seu WhatsApp no seu principal canal de vendas e reduza custos com apps de delivery e marketplaces. Esteja presente no aplicativo preferido dos consumidores enquanto transforma mensagens em vendas.
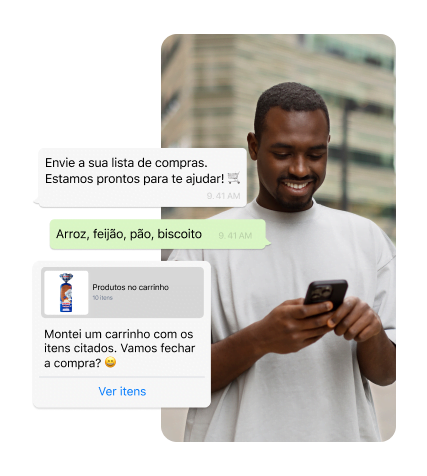

Nossa IA Generativa ajuda seus clientes a encontrar o que precisam, sem intervenção humana, mesmo que você tenha milhares de produtos. Economize recursos, venda mais e gere novas experiências de compra.

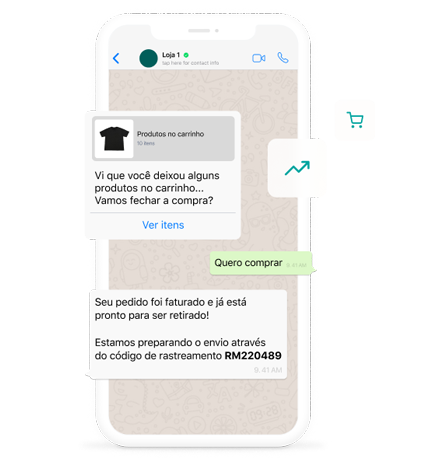
Recuperação de Carrinho
Maximize ROI e conversões de vendas enquanto minimiza o abandono de carrinho. A IA da Weni envia mensagens automáticas para clientes que não finalizaram as compras na loja online, ou física.

Geolocalização
Use a localização geográfica do cliente a seu favor. Filtre resultados e estoques para oferecer itens disponíveis nas proximidades, reduzindo o tempo e os custos de entrega.

Faq automático
Automatize respostas sobre taxas de entrega, garantias estendidas, preços e tempo de entrega. Ocupe seu suporte com o que realmente importa.

Atualizações em tempo real
Forneça informações automáticas e em tempo real sobre faturamento, pagamento, entrega e cancelamentos. Reduza as perguntas frequentes e construa uma relação de confiança e credibilidade.

Recomendações inteligentes
Use o histórico para recomendar produtos e adicionar oportunidades de upsell, como refis, itens úteis e promoções personalizadas.

Disponibilidade em estoque
Notifique seus clientes quando os produtos preferidos deles estiverem disponíveis no estoque.

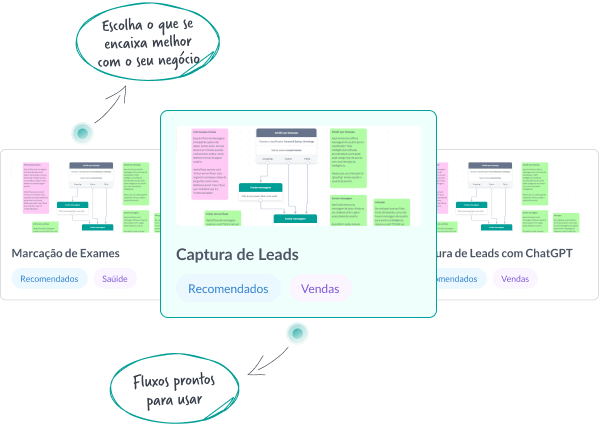
Você não precisa começar um fluxo ou chatbot do zero!
Na nossa galeria de templates, você encontra modelos de fluxos prontos, já com as principais integrações, incluindo inteligência artificial, WhatsApp Demo e API do ChatGPT.
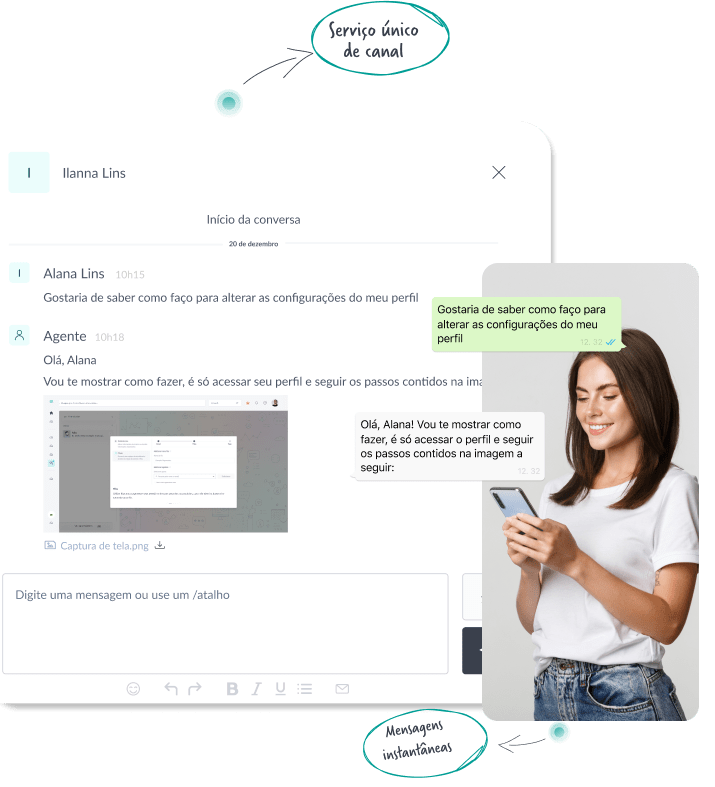
Com o Weni Chats, seus agentes de atendimento podem esclarecer dúvidas, auxiliar em compras e devoluções, e centralizar o atendimento de canais, como WhatsApp e redes sociais.




VK
Webchat
Jiochat
Telegram
Viber
Line
e mais…
Se o seu projeto precisa se conectar ao WhatsApp ou migrar a API, traga a sua conta para a Weni e evolua o atendimento com quem entende e é Business Solution Provider (BSP) oficial do mensageiro.









Copyright © 2022 Weni. All rights reserved.